Cisco Network Services Orchestrator (NSO) - YANG - Part 2
An in-depth dissection of a yang data model.

In this post, let us try to further concepts introduced earlier. We started looking at the way a yang data model is structured. In this article let's take a sample yang model and try to understand it part by part.
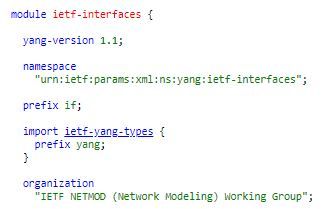
MODULES, PREFIXES
We first start with the modules. A module can comprise multiple sub-modules. Every module needs to be uniquely identified by a namespace. This will help to differentiate this yang model from many other models that may reside in the system/device. The prefix is sort of a shorthand notation we would use to reference this namespace subsequently in this module.
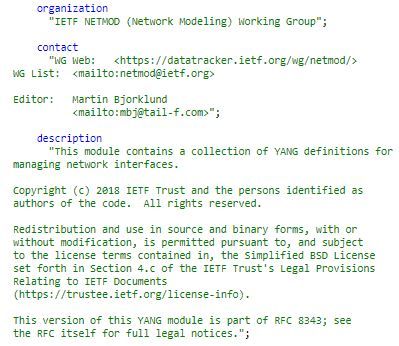
ADMINISTRATIVE CONTENT IN YANG HEADER
The module header can include administrative content like organisation, contact information etc. The revision field can help us uniquely identify the revision of the module. Including revision- fields can help prevent any mismatch between the devices that are talking NETCONF protocol. How? During the initial hello exchange the devices involved in NETCONF exchange their data models and capabilities and any mismatch in revision in the yang header can be easily identified by the devices.

IMPORT / INCLUDES
Then there is the concept of imports and includes. Import statements are used when we want to reference definitions from another yang file. It is used to just reference; so the entire body of the referenced file is not pulled into the referencing yang module. This is especially useful when we write a module that supposedly contains a common theme and we can reference it in multiple other modules for clarity.
On the other hand, include statements are used to pull in the parts of the yang file spread over multiple files. The included sub-modules are stiched and pulled together into the referencing module when an include statement is used.
What's the need for a sub-module?
Sub-modules allow the writer to split a big complex model design into several small sub-modules. All such sub-modules combine and contribute to the module that calls the sub-modules using the previously introduced "include" statement.


Notice how the sub-module does not have the name-space declaration, instead has a belongs-to statement. A sub-module can belong to only a single module.
DATA TYPES SUPPORTED IN YANG
Yang supports most of the common data types integer, unsigned integer etc. All supported base types have been defined in RFC 6020. Some of the supported data types are:-
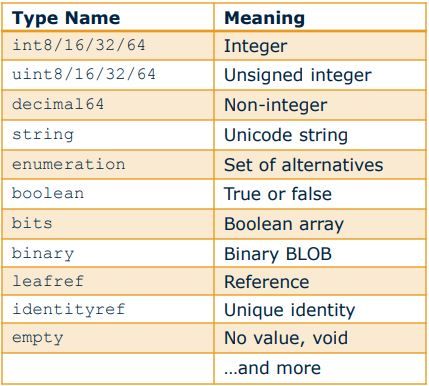
The final element of yang that stores the data (ex leaf) can store a base type or a derived type. A derived type can be defined by a typedef or grouping. We will not be looking into groupings at this point in time.
TYPEDEF
Typedefs are used to define a new derived data type using the base type with some restrictions. Let us see this example to understand better:-

In this typedef, the author has tried to impose a restriction on the values the defines datatype "per cent" could take using the range keyword. Later we see the leaf "completed" taking the type of the newly defined "per cent" using the type keyword. Several modifiers can be used to play around with the restrictions. If we come across a yang file we can always google to find out the meaning of that modifier or keyword to understand the restrictions it brings to the table. When one derived data type references another derived datatype previously defined, the restrictions of the new derived type are applied on top of the restrictions posed by the mother derived data type.
UNION STATEMENT
If we require our derived data types to be either of two base data types then we can mark such restrictions using a union statement. Let's take a look at this example:-

In the above example, we try to define a new datatype called "threshold" which can hold values that either belongs to the unsigned integer base type with restriction of (0 to 100) or it can be of type "enumeration" which can hold one of the enum type called "disabled".
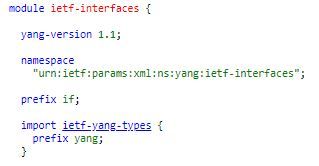
Apart from the base types defined in RFC 6020, the working group thought they should build a module for the commonly used objects of the networking world. This module is named "ietf-yang-types". So anybody who wishes to use these definitions in their modules can go ahead and import them. Remember the "ietf-interfaces" module that we took a look at in the initial part of this article. Notice how it imports the ietf-yang-types module and assigns a prefix "yang" to it. This the convention mostly followed when one imports the "ietf-yang-types" module:-
You can take a look at the "ietf-yang-types" module here and go through the derived datatypes the writers have created.
When we want to utilise one of the derived types from the imported module we should append the prefix for that module followed by a colon ":" to uniquely reference the definition from that module. Example:-
type yang:counter64What are leaves?
A leaf node contains simple data like an integer or a string. It has exactly one value of a particular type and no child nodes.
The YANG language provides two constructs that can hold data namely the leaves and leaf lists. First, we see an example of a leaf definition and an XML instance of the leaf called "enabled".
leaf enabled {
type boolean;
default true;
}<enabled>false</enabled>A leaf node can have atmost only one instance but a leaf-list can have multiple instances. Here we see an example of leaf-list definition followed by an example XML instance:-
leaf-list cipher {
type string;
}<cipher>blowfish-cbc</cipher>
<cipher>3des-cbc</cipher>Then what are non-leaf constructs?
Non-leaf type constructs are those that can have references to child nodes but cannot take in a value. Only leaves can take in value. So what are the non-leaf constructs? They are containers and lists.
Let us see about containers. A container mode is used to only group some other nodes (child nodes). So what are all the options for child nodes? A container can contain leaves, leaf lists, the container itself or lists(we haven't seen lists yet). Remember, a container can only have child nodes but cannot take a value on its own. Let us take a look at a definition of container followed by a sample instance.
container system {
container login {
leaf message {
type string;
description
"Message given at start of login session";
}
}
}See how the container named "system" references another container named "login". This is a valid definition. Further, the container "login" references a leaf child node that will contain the value. Let us see a sample XML instance of the container defined above:-
<system>
<login>
<message>Good morning</message>
</login>
</system>See how the string "Good morning" is contained within the leaf named message.
So then what is the other non-leaf type? It's the list. If you are familiar with python you can think of a dictionary object at the back of your mind to augment the understanding of this yang construct. In the likes of a container a list cannot have value but can have child objects. The child objects can be a leaf or list or a container (any number of them) . In a python dictionary, how do you uniquely identify an object inside the dict object? We use a key to reference an object and get its value. Similarly, the list construct also allows us to define the key attribute.
Let's quickly look at an example to understand better:-
list user {
key "name";
leaf name {
type string;
}
leaf full-name {
type string;
}
leaf class {
type string;
}
}In this list called user, we have defined multiple child objects (In this case three leaves have been defined). But out of those, the leaf called "name" has been defined to be the key attribute for this list. Let's take a look at a sample XML instance:-
<user>
<name>glocks</name>
<full-name>Goldie Locks</full-name>
<class>intruder</class>
</user>
<user>
<name>snowey</name>
<full-name>Snow White</full-name>
<class>free-loader</class>
</user>In this case, multiple entries of this list can be uniquely identified by the "name" attribute.
We have come a long way in understanding the basic constructs, data types and parts of the yang modelling language. It is always tough to learn theory, isn't it ? The last two parts of this series have been heavily theoretical but I am sure it will help us in understanding the working aspects of Cisco NSO. We have not dwelled into the complete intricacies of yang modelling language; we will look into it further in future if there is a need.
In the next article, we will look into some practical aspects of NSO, start getting our hands dirty. Do let me know your suggestions and comments. If you come across any technical inaccuracies please point them out, I will do my best to correct them as soon as possible. It will help many others in the community. Thanks.